
In the digital world, search engine optimization is an important part of driving traffic to your website. But there may be certain parts of your site that you don’t want search engines to index, or perhaps you want certain pages to be prioritized over others. This is where robots.txt comes into play.
Robots.txt is the file used to communicate with web crawlers about which URLs on a website should or should not be crawled or indexed by search engines. You’ll find the file stored in the root directory of your website, and it can contain specific instructions for different search engine crawlers.
Robots.txt is important because it can help protect your website’s privacy and security, as well as ensure that your site is crawled and indexed as efficiently as possible.By blocking certain pages or directories from being crawled, you can prevent sensitive information from being exposed to search engines and reduce duplicate content issues. By not allowing all pages to be crawled, you can make sure search engines find the most important pages on your site.
Robots.txt should be used as a tool, a cornerstone of your work but also a strategy. It’s important to keep in mind that the file is a living document. By understanding how to use robots.txt in an optimal way, you give yourself an advantage with search engines.
In some cases, you’ll need to have private pages, for example, a login page or admin page that only you or the owner should access. Since you don’t want Google or other search engines to find these, you can use robots.txt to block crawlers.
By blocking unnecessary pages, or those that don’t need to “take up space” on your website, you ensure that bots can prioritize your more important pages, thereby maximizing your crawl budget. The more pages and subpages your site accumulates, the more important it becomes to identify which ones don’t need to be crawled and block them in your robots.txt file.
It’s important to remember that robots.txt is not a foolproof method for protecting your site. Web crawlers may ignore or misinterpret your instructions, and malicious bots may completely disregard the rules in the file. Googlebot and other major crawlers strictly follow robots.txt instructions, but it’s not guaranteed that others will. We therefore recommend protecting your private files and pages using additional security methods, such as password protection and/or IP blocking.
Although most crawlers follow the rules in a robots.txt file, each search bot may interpret the rules differently. You should know the correct syntax for addressing different web crawlers, since some may not understand certain instructions.
Googlebot will not crawl or index the content that is blocked by a robots.txt file. However, it can still discover and index a forbidden URL if it’s linked from other places on the web.To properly prevent your URL from appearing in Google’s search results, you should protect the files with a password, use the no-index meta tag, or alternatively remove the page entirely.
Of course, you can test your robots.txt for errors. It’s always good to double-check this so you can avoid mistakes that cost time in indexing or other issues.
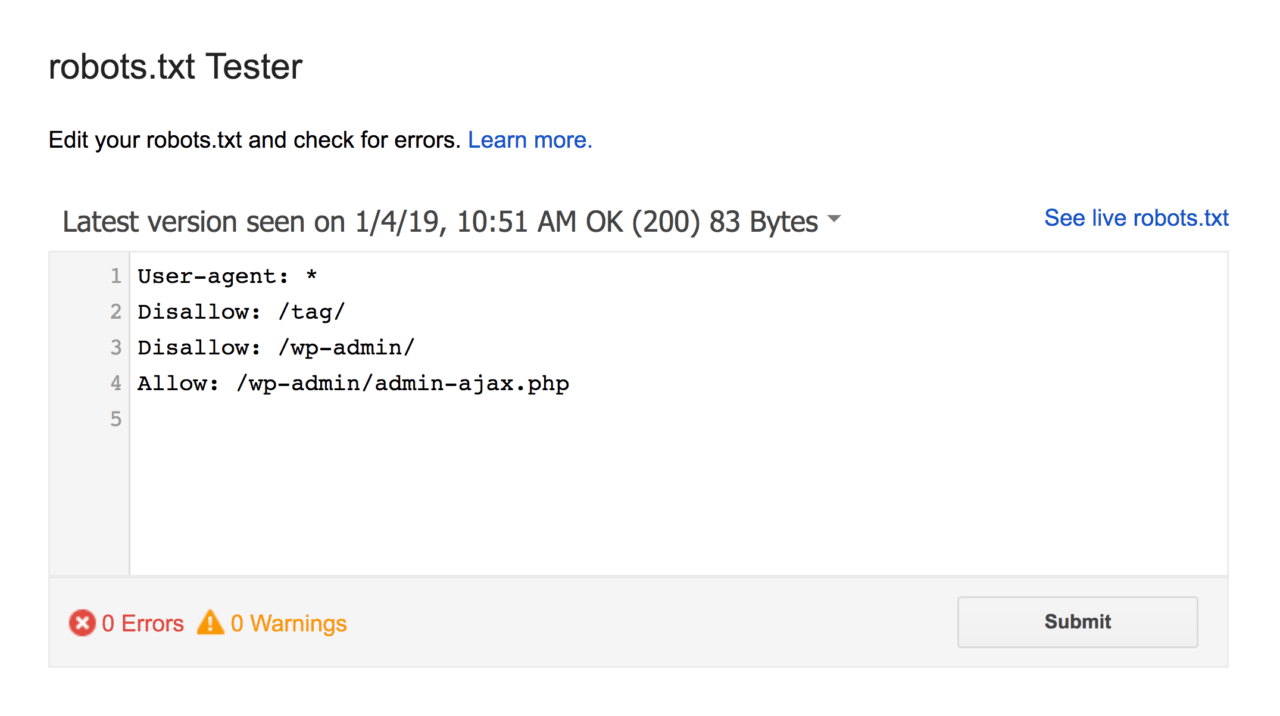
To create a robots.txt file, you need a basic text editor, such as Notepad or TextEdit. You should save the file as "robots.txt" and place it in the root directory of your web server, which is usually accessible at "www.example.com/robots.txt".
The syntax consists of three elements: User-agent, Disallow, and Crawl-delay.
User-agent: *
Disallow: /wp-admin/
Sitemap: https://www.example.com/sitemap1.xml
Sitemap: https://www.example.com/sitemap2.xml
Robots.txt is an important file for communicating with crawlers about which pages should or should not be crawled by search engines. By creating a robots.txt file, you can ensure that search engines find the most important pages on your website and protect your website’s integrity and security by blocking access to sensitive information.
Creating a robots.txt file is a relatively simple process that can be done with a regular text editor and placed in the root directory of your web server, but most often you will find it already set up when using different CMS platforms.